
Euclidean Technologies Management letter to investors for the second quarter ended June 30, 2019, titled, “Forecasting Uncertainty.”
In this quarter’s letter, we discuss Euclidean’s continuing research on forecasting companies’ future earnings. This research builds on our previous work showing how machine learning can be applied to forecast future company fundamental data, such as earnings, from past fundamental data. While we have been reviewing the impact of allowing the learning process to explore certain additional datasets, such as industry classifications and macroeconomic trends, the primary development we discuss in this letter involves the concept of uncertainty.

Q2 hedge fund letters, conference, scoops etc
Obviously, companies’ future paths are uncertain. They are complex entities operating in complex systems associated with customer demand, industry structure, and the overall economy. Thus, as seen in the record of Wall Street analysts, predictions of future earnings rarely hit the mark. [1] However, in other complex domains – such as weather forecasting, managing supply chains, and predicting transportation demand – forecasting has become progressively more effective as researchers leverage techniques that acknowledge the futility of point forecasts and instead focus on estimating probabilities for a range of outcomes.
In the research we describe here, we apply insights emerging out of other uncertainty-laden domains to estimate a range of possibilities for companies’ future financial results. Our objective is to improve our models for evaluating potential equity investments by better applying traditional valuation concepts, such as margin of safety, in a process-driven manner.
Why Forecast?
When evaluating companies as potential investments, we can look at their pasts. We can compare them to other companies that looked similar and consider how they performed as investments. But, ultimately, the way today’s companies evolve and how their share prices perform will be driven by future developments we cannot observe in advance.
So, in this sense, the work we do reviewing data and looking at comparable situations from the past is to help us anticipate the future. We seek to establish base rates for how companies with certain sets of characteristics, when offered at certain prices, typically have performed. We then invest in companies with favorable comparables, believing that doing so puts the long-term odds on our side.
However, this is all just a proxy for what ultimately matters, which is simply whether a company's future earnings develop more or less favorably than the market expects. Yes, some companies trade on revenues or developments other than earnings, but over time, companies’ long-term market values generally have moved toward what their earnings dictated. [2] Thus, as aligns with common sense, it seems that the better you can forecast earnings and invest in companies that are priced low in relation to those future earnings, the greater your opportunity for future returns.
We proved this to ourselves by running simulations with a clairvoyant model that accesses future financial reports. To be clear, this was nothing more than an exercise to estimate the theoretical upper limit of investment performance if you could accurately predict earnings one-year into the future. In Figure 1, we demonstrate that from Jan 1, 2000 to Jan 1, 2017 [3], an EBIT (earnings before interest and taxes) / EV (enterprise value) factor model that uses perfect 12-month forecasts (a clairvoyant forecast) for EBIT would, if possible, achieve a 44% compound annualized return. That compares to a 14.7% annualized return over the same period for a traditional EBIT/EV factor model using trailing 12-month earnings instead of future earnings. [4] As you can see, the further in the future one could predict future financial performance, the higher the theoretical returns appear to be.
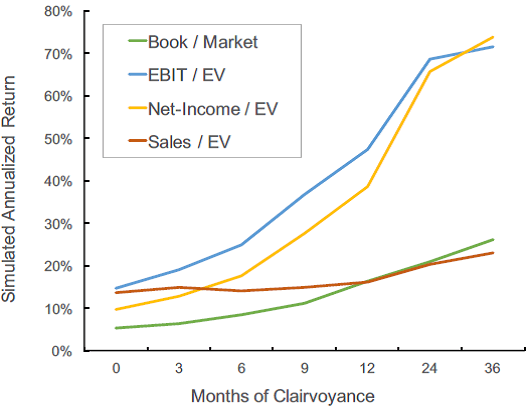
Figure 1
Why Estimate Uncertainty?
The fact is, these theoretical returns are out of reach. It is hard to successfully predict the future. Experts don’t do it well. Forecasts by market “gurus” are accurate less than half the time [5], and even CFOs demonstrate an astonishing inability to predict where the market will be 12 months from now [6]. Wall Street analysts average >30% errors in their earnings-per-share forecasts and our experiments with algorithmic approaches, which may deliver better earnings forecasts than those of human experts, still have average error rates exceeding 20%. [7]
So, what’s the point of this exercise? Well, even if the theoretical clairvoyant returns are not attainable, we still want to capture as much as possible of the potential return they imply. And, given the difficulty in making accurate point forecasts, we wondered what might come from estimating the uncertainty in earnings forecasts and better understanding the probabilities for a range of potential outcomes.
Thankfully, we can learn from the growing body of work in other domains.
Hurricane Forecast Cones and Uber Demand
What motivates a meteorologist to generate the cone around the potential path of a hurricane as opposed to predicting the most likely path? Perhaps it’s that specific forecasts regarding a hurricane’s path almost always would miss the mark, leaving large populations with a false sense of security and limiting emergency personnel’s ability to plan for multiple scenarios. With better tools, more data, and increasing computing power, hurricane forecasts have become progressively more accurate, able to narrow the cone of likely paths and to project hurricane cones further into the future. [8]
The familiar hurricane cone provides a good analogy for what some technology companies are attempting to accomplish with deep learning. [9]
For example, Uber has significant challenges in forecasting demand given that the day of the week, holidays, weather, special events, and many other factors come together to determine how many riders will seek rides from Uber at any given place and time. If Uber’s forecasting ability is poor, then it either will create a lot of unhappy drivers – who will not have enough demand to maximize utilization – or unhappy riders, who cannot find a ride home.
Uber has a two-part challenge that Euclidean shares. First, while uncertainty estimation using classical time series models has been widely studied [10], this is not the case in the domain of machine learning. Second, Uber found that classical forecasting models were not robust enough to provide the insights they require. Thus, they explored how to use machine learning, informed by a combination of historical data and external factors, to make better predictions.
Uber has published many important insights from their research. Their findings include:
- Long-Short-Memory Networks [11] improved the accuracy of their forecasts compared to traditional forecasting methods. [12]
- Bayesian Neural Networks enabled Uber to move beyond making point forecasts and begin successfully quantifying varying uncertainties associated with the distribution of future demand. [13] As a result, Uber has significantly reduced the amount of error involved in matching supply to demand with an appropriate margin of safety. [14]
This second point gets to what Euclidean has been eager to accomplish in forecasting future earnings for individual companies.
Forecasting Uncertainty at Euclidean
In prior research, we used deep learning to forecast companies' future earnings, then used those forecasted earnings in a traditional factor model. Specifically, we trained a deep neural network to forecast companies’ next year’s earnings-before-interest-and-taxes (EBIT) for the following year. We then calculated the ratios of companies’ forecasted EBIT to their enterprise values (EV) and sorted the universe of companies by this ratio (EBIT/EV). Companies with the highest ratios would be thought of as the best “value stocks,” and we showed that simulated portfolios based on forecasted EBIT performed better than models based on companies’ trailing 12-month EBIT.
While these results were encouraging, we knew that making point forecasts of companies' future earnings left out important information that could make for better investment decisions. Our models had no way to express how much confidence we should have in each individual company’s forecast. After all, two companies with very similar earnings point forecasts may represent different kinds of opportunities, with very different risks. We might expect future earnings to be more predictable for an established utility than for a new company or for a company operating in a highly cyclical industry. Moreover, we might expect the range of likely future earnings to be different for the same company at different times, perhaps becoming more difficult to predict following a large acquisition, the expiration of a patent, or as the economy moves from a period of stable growth into a time of change.
So, just as weather forecasters use data to construct hurricane cones, we set out to develop a process to estimate the distribution of a company's future earnings. This probability distribution has both a mean and variance. Therefore, when attempting to quantify the uncertainty in a forecast, we no longer forecast a specific value for future earnings. Instead, we attempt to learn the mean and variance of possible future values. With the mean and variances in hand, we can construct “earnings cones” (or credible intervals) in which actual earnings will fall within a set percentage (e.g., 75%) of the time.
Sample outputs for individual companies are shown below. The orange lines show the actual trailing 12-month EBIT for each company at each point in time. And, the blue lines show what our model’s mean forecasts were, one year ahead of the company’s actual results at each point in time. The shaded areas around the blue lines show the model’s calibrated[1] credible intervals (hereafter, just credible intervals) around each mean forecast. The darker shaded area is one standard deviation from the mean, and the lighter shaded area is two standard deviations. The total shaded interval around the mean contains approximately 80% of the company’s actual earnings.
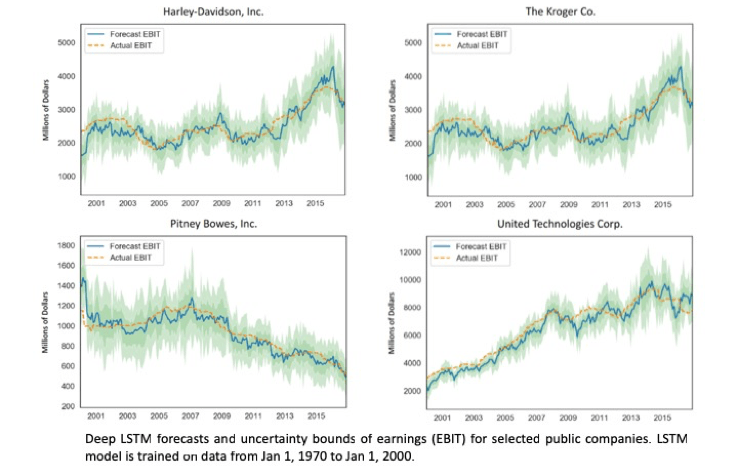
Our research into how to best estimate the uncertainty in earnings forecasts is ongoing. We are seeing that certain additional datasets and a variety of sensible adjustments to prior years’ operating earnings provide the opportunity to improve and tighten these forecast cones. Moreover, there are a variety of potential ways to use these forecasts to improve how we invest. Let’s explore one.
How Uncertainty Estimation Might Improve A Value Factor Model
When thinking about investing in the context of the hurricane and Uber analogies, a common concept emerges – the idea of margin of safety. All three domains are complex enough and are subject to such a variety of exogenous factors, that holding any specific prediction too tightly is an easy way to get into trouble. Thus, in all three domains, it’s common to use prior experience in estimating the range of potential outcomes, and then operate so that you can be successful across that range.
In a sense, certain traditional quantitative value strategies already seek a margin of safety by investing in companies offered at the lowest prices in relation to their prior-year earnings. Over the past half-century, that approach would have been a very effective method of investing [16], and a window into its performance shows up in the Traditional Factor Model’s simulated results below.
To improve on this traditional approach to quantitative value – in this case, one that selects companies with high ratios of EBIT to Enterprise Values (EBIT/EV) – we explored taking our previous earnings-forecast work one step further by explicitly introducing the concept of margin of safety using our uncertainty forecasts. We did this by using a more conservative forecast of companies’ future EBIT, defined at the lower-bound of the 50% credible interval around the model’s mean predictions. This meant that, by design, companies’ actual earnings would be higher than our forecasts approximately 75% of the time. By using this more conservative approach, companies with less-certain earnings forecasts (and wider credible intervals) will be ranked lower – and will be less likely to be included in simulated portfolios – than they would in either Traditional Factor Models or our previous simulations using the mean forecast.
Here are some high-level simulated results, reflecting 50-position portfolios using four different methods for ranking value stocks.
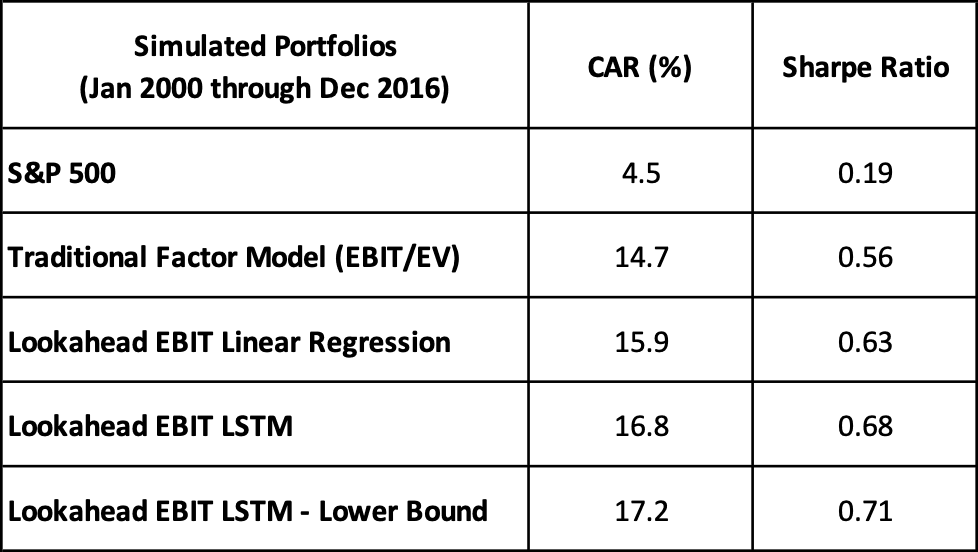
In these simulations [17] [18], the three methods of using forecast, or “lookahead,” EBIT all perform better than the traditional factor model, which uses companies’ trailing 12-month earnings. Also, using the lower bound of the earnings-forecast cones results in somewhat higher returns and Sharpe ratios than what we previously saw when making point forecasts.
Notably, in other experiments that employ different machine learning architectures and include other datasets (e.g., analysts’ estimates, macroeconomic data, and other company-related non-financial information) not reflected in these results, we are seeing that the simulated returns and Sharpe ratios are consistently higher using the lower bound forecasting approach.
***
We have evolved our investment process over time to incorporate new learning. Even as we stand today, confident in our process and optimistic that the environment eventually will be supportive of our deep-value approach, Euclidean remains devoted to learning. We continue to seek the best methods for uncovering history’s lessons and overseeing a systematic process that reflects what we have found.
Best regards,
John & Mike
The opinions expressed herein are those of Euclidean Technologies Management, LLC (“Euclidean”) and are subject to change without notice. This material is not financial advice or an offer to purchase or sell any product. Euclidean reserves the right to modify its current investment strategies and techniques based on changing market dynamics or client needs.
Euclidean Technologies Management, LLC is an independent investment adviser registered under the Investment Advisers Act of 1940, as amended. Registration does not imply a certain level of skill or training. More information about Euclidean including our investment strategies, fees and objectives can be found in our ADV Part 2, which is available upon request.
This article first appeared on ValueWalk Premium












