
New technologies depending on intelligent tools based on IoT (Internet Of Things) and Artificial Intelligence (AI) has brought more security threats and risks in computing. Extensive use of cloud services and machine learning algorithms also pose a higher threat to data security and risks of data loss can be envisioned. One of the most significant and destructive threats it poses is that our private information is at risk like never before and since last decade or so it has seen hundreds of cases of identity theft, loss of money, and data breaches.
Cyberattacks in nature are very pervasive and affect every individual, business, and government bodies alike. Such high-level threats gave way for the intersection of machine learning and cybersecurity to induce better automation of cybersecurity.
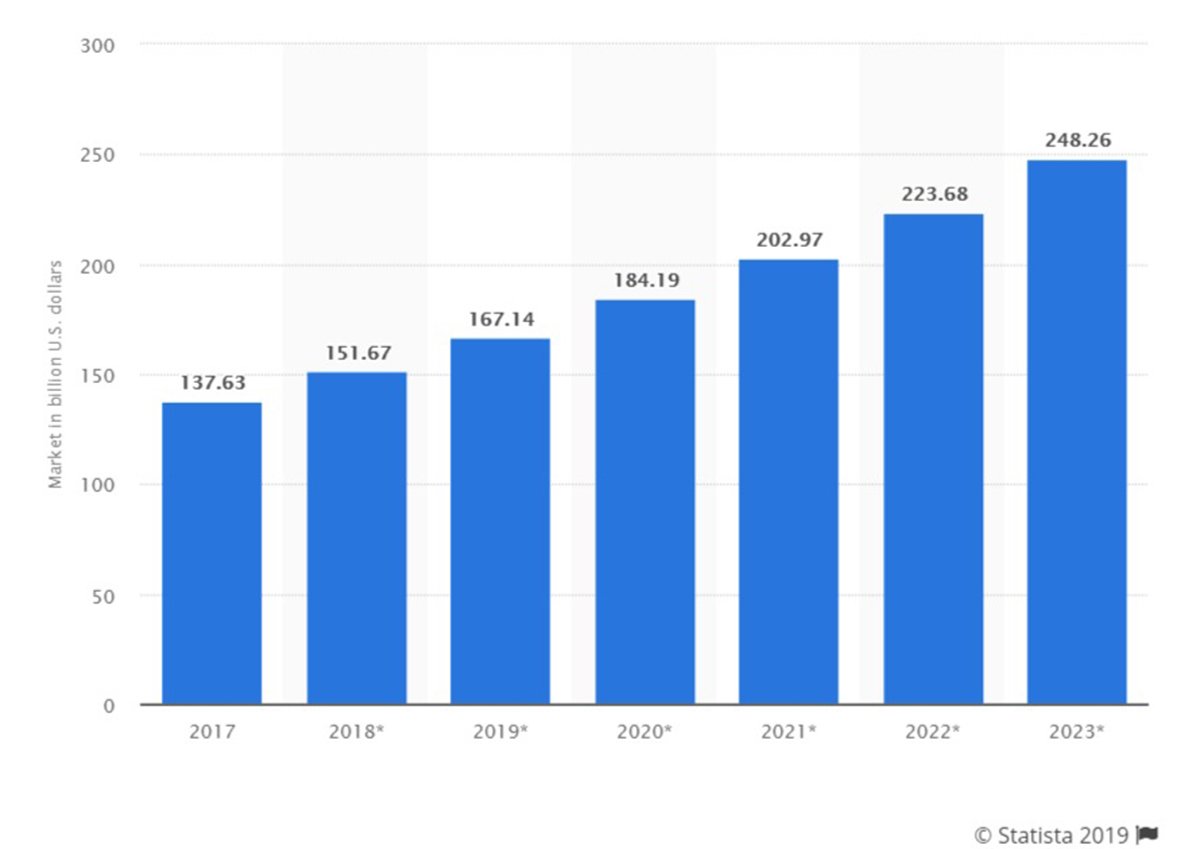
Due to BigData being collected from different sources, the development of a tool that can effectively detect anomalies in the system and classify them automatically becomes extremely difficult. Cybersecurity as a practice to defend the organizational networks from such anomalies have gained momentum over the years. The global cybersecurity market size has been on the rise and as per Statista, it is predicted to rise to $248.26 billion by 2023.

Q3 2019 hedge fund letters, conferences and more
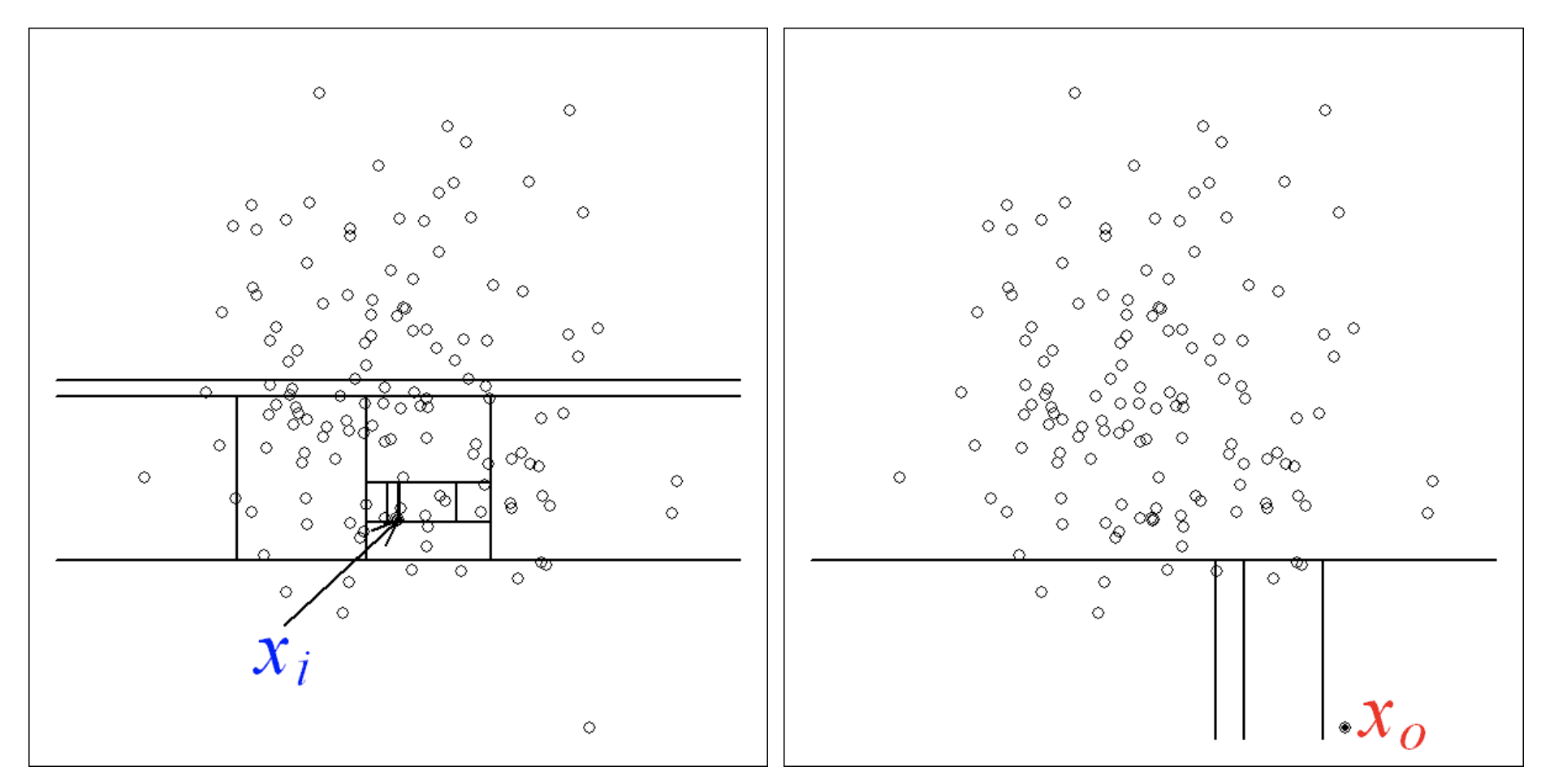
A common practice in the cybersecurity realm is to determine whether a user has non-secure access to the network or not. This is done by detection of anomalies in the network which is detected through the process of data through various algorithms that help, the systems detect an outlier. An outlier in a dataset is defined as an observation that is unique, compared to the other remainders. Mining of outliers is an important data mining practice for real-life applications like credit card frauds, e-commerce frauds, and customer segmentation.
Organizations and enterprises need a platform to detect such anomalies in the current state and compare them with historical data to determine the severity and threat of the anomaly to alert the system.
CyberSecurity Autonomous Machine Learning platform(CAMLPAD):
CAMLPAD systems are platforms that retrieve different types of cybersecurity data in real-time, using techniques like elastic search and then uses Yet Another Flowmeter (YAF) data to process PCAP data and end export the dataflows to IPFIX (a data collecting process). Further, this data is run on several different machine learning algorithms like Isolation Forest, Histogram based outlier score, cluster-based local outlier factor, and Angular-based outlier detection to process this data. Anomalies are then visualized using Kabana and are assigned an outlier score.
This outlier score indicates the algorithms of whether or not an alert should be raised to the system administrator regarding an anomaly in the network. CAMPLAD also uses frameworks like BRO and SNORT, which are both anomalies and threat detection frameworks that are used to find risks and threats in the network. The entire system is maintained and facilitated on Meraki, which is a cloud-based centralized management service with a network and organized structure.
It provides an accurate, streamlined approach to real-time cybersecurity detection of anomalies and threats for developers and cybersecurity professionals that can give restricted access to a user, who might not have the needed authorization for the same.
Machine Learning Algorithms for Cybersecurity:
1. Isolation Forest:
It is an algorithm that explicitly identifies anomalies instead of just profiling normal data points. It is a decision-tree based-method, in which several partitions are used among the randomly selected features of a system. Then a random split between the maximum and minimum value of partitions.
The use of such random partitioning can help identify anomalies closer to the root of tree and Isolation of normal points from anomalies becomes more difficult due to the requirement of high computation over a broader spectrum. An anomaly score measures the number of scenarios that separates the anomaly from normal point. The algorithm specifically begins by creating random decision trees, and then the score is calculated by being equal to the path length to isolate the observation.
2. Histogram-based outlier detection:
It is an algorithm that scores records in linear time by assuming the features to be independent to make it faster than multivariate approaches. It is observed that histogram-based outlier detection is efficient in global anomaly detection problems. But, it is not efficient enough to detect the local outliers. Though it is much faster than other standard algorithms for large datasets.
The cybersecurity network needs instantaneous detection of outliers through the machine learning algorithms. Also, the datasets to be processed are very large due to BigData. Histograms are thus, used extensively as a density estimator for semi-supervised anomaly detection.
3. Cluster-based local outlier detection(CBLOF):
It is an intuitive algorithm that provides support to local data behavior, which is quite different from histograms. It is a measure to identify the physical significance of an outlier. CBLOF uses clusters to find anomalies in data points by measuring the local deviation of a given point with respect to its neighbors.
It uses the concept of local density of an object from k-nearest neighbors by comparing densities of neighbors in order to identify regions of similar density. Broadly, speaking, it identifies the difference in data clusters by comparing one data cluster with the nearest possible cluster and find similar regions to know the difference in them.
4. Angle-based outlier detection:
It is a distance-based approach to outlier detection. In this algorithm, there is a necessity to provide scalar product for comparison of data objects, which seems to be more restrictive than providing distance measure. It introduces the concept of angle comparison between pairs of distance vectors to other points.
This helps discern points similar to other points and differentiate the outliers. This algorithm helps avoid the curse of dimensionality i.e. that a large amount of data needs large dimension algorithms to process and created huge computation complexity, which is solved by the use of an angular approach to dimensional detection of an outlier.
Machine learning algorithms - Conclusion:
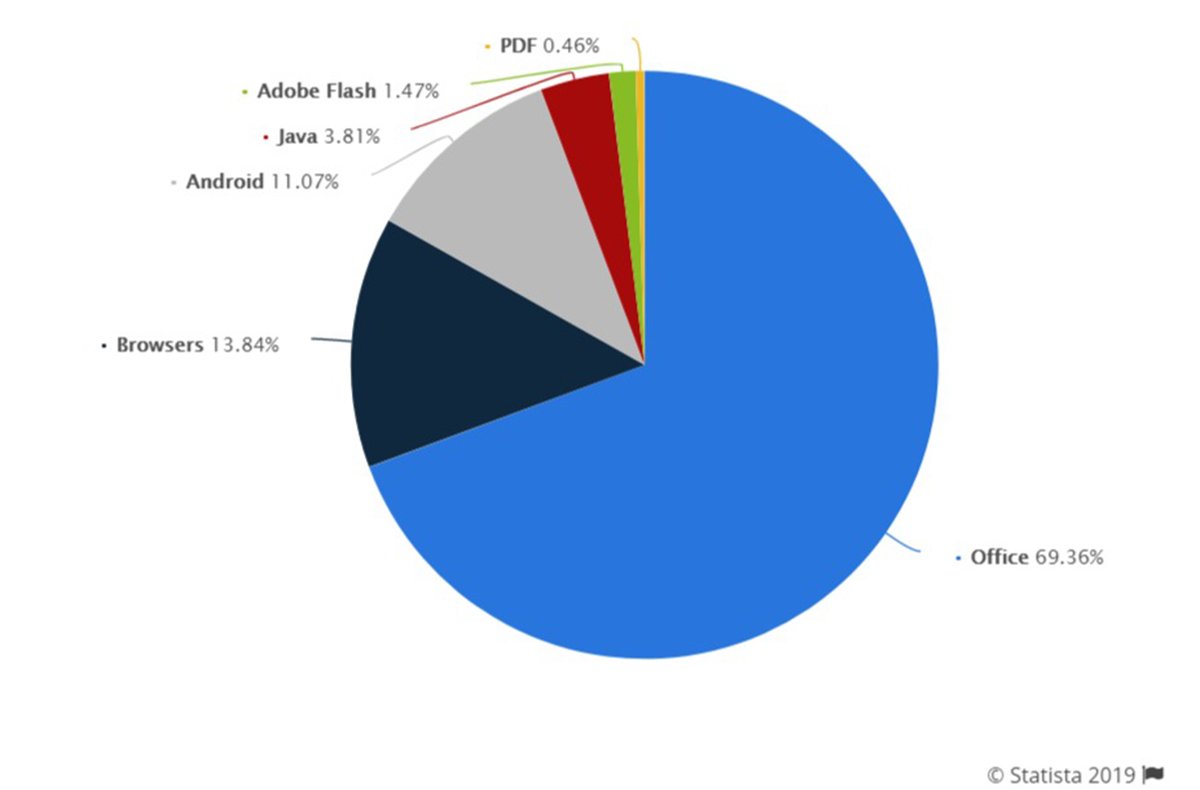
There are several security breaches and cybersecurity threats looming over the systems worldwide. According to Statista, out of cyberattacks worldwide 13.84% amounts for browsers, where users share their data through web-services and a major part of data risk is on office amounting of 69.36%. CAMLPAD is an attempt that can effectively detect anomalies in real-time resulting in higher security of data.
The statistics of cybersecurity markets by Statista states that spending in the cybersecurity industry reached around 37 billion U.S. dollars, with forecasts suggesting that the market will eclipse 42 billion by 2020. This data shows the sincerity of enterprises globally into making robust cybersecurity systems that can detect threats before dangerous outcomes.
About the Author
Manoj Rupareliya is a Marketing Consultant and blogger. who has been writing for various blogs. He has previously covered an extensive range of topics in his posts, including Business, Technology, Finance, Make Money, Cryptocurrency, and Start-ups.
Linkedin | Twitter












{kind=link}
{kind=link}
{kind=link}