With so many alternative data sources on the market, it can be tempting for users to overbuy and horde, however, sticking with the same set and trying to master it can sometimes yield dividends.

Q1 2020 hedge fund letters, conferences and more
Alternative Data Sources: Dig Deep or Move On?
There used to be a time where novel datasets were sought out by fund managers hungry for the alpha-advantage they promised, however, things have changed and now there are more vendors than buyers, and in this new environment of over-supply, there can be a tendency for users to endlessly seek novelty, moving from vendor to vendor without properly wringing out all the value from their existing datasets.
Users can sometimes be guilty of a ‘plunder, pillage and move on’ culture when it comes to alternative data sources, according to Peter Hafez, Chief Data Scientist at RavenPack.
“There is pressure to try to get the research and production into signals as quickly as possible,” says Peter. “So they can show management we are making money, that we are making more money than what we are paying for it, and that is, of course, great. They may have a multiplier - we need to make 5x more, 10x more. But then often you move on and say, now I need the next dataset.”
Rather than moving on to the ‘next alternative data source’ however, it often actually pays to stick with the old dataset and see if you can extract more value from it.
“Perhaps it is better to invest your resources on somewhat proven datasets and say ‘now I want to become an expert’ in that because a lot of these datasets are rich and can be used in many different ways,” says Hafez.
It is, of course, true that datasets come in all shapes and sizes and some are one dimensional with limited applications, however, this is not the case with RavenPack, which provides news data analytics on over a quarter of a million entities and events, including companies, securities, countries, and people. Indeed the firm spends a great deal of time structuring, tagging, and co-referencing its data precisely so end-users can extract as much value as possible from it.
“We do a lot of work around entity detection. We don’t really detect securities we detect entities. Those could be companies, or places, or organizations, currencies or commodities. In order to make it easier for our clients to consume our data we also provide mapping files,” says Hafez.
RavenPack’s entity management is sophisticated enough to distinguish between brand name and company name changes.
“All of these small nitty-gritty things of maintaining your entity universe, such as how Gillette was Gillette until it got bought up by Procter and Gamble. All of that work - we have a huge team that are also providing a lot of human intervention - it is part of our value-add.”
A major USP of the dataset is its co-referencing analytics which allow it to quantify the degree of relatedness between two entities connected by supply-chain, sector or competition. This can provide users with an information advantage when it comes to quantifying the knock-on effect of events on related securities.
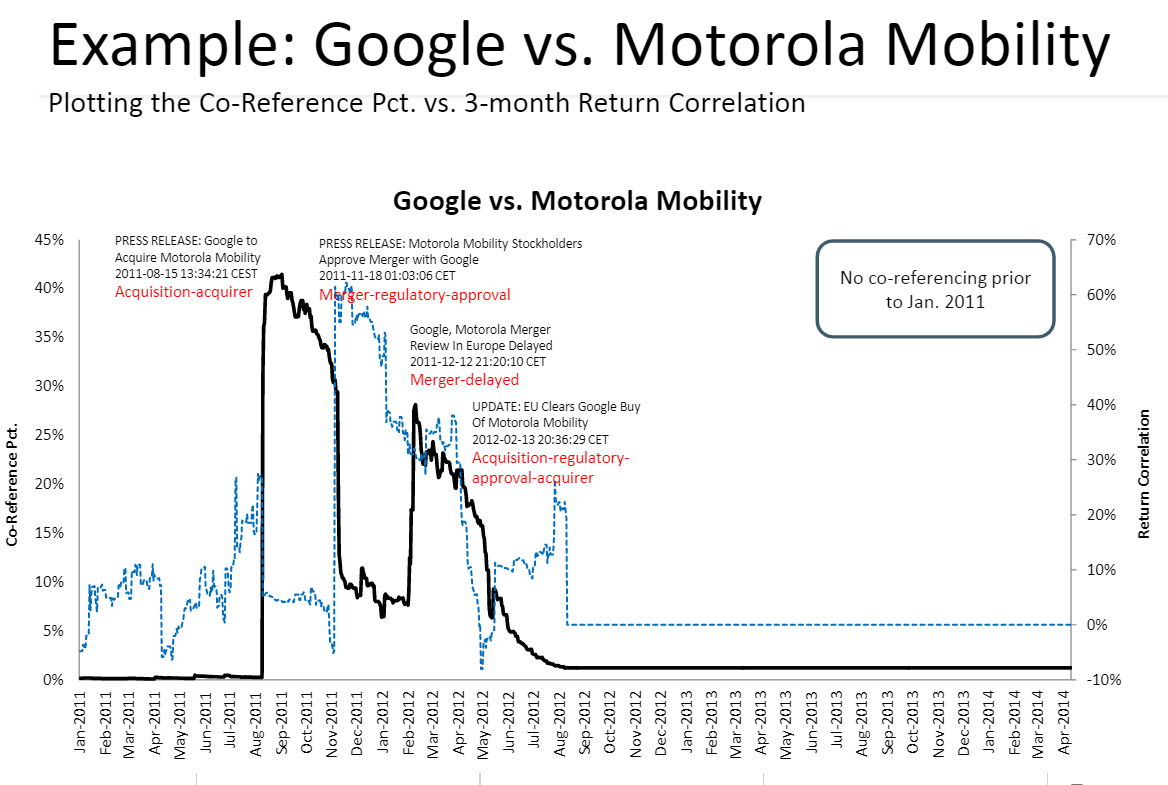
Users can build strategies or take advantage of trading opportunities by analyzing the percentage of news stories which co-reference two companies’ names over time and correlating that to the companies’ stock returns, as shown in the plot below for Google and Motorola when the former acquired the latter in 2012.

Source: RavenPack 2014
As can be seen from the chart above, co-references of Motorola and Google, represented by the thick black line, peaked before the two stock prices did, which are represented by their ‘correlated returns’, and this essentially provided a warning of the merger to come.
A Few Good Sets
Whilst becoming an expert on one dataset is undoubtedly a sound strategy, striking a balance between by mixing a few high quality datasets together often actually yields the best results so it is not a good idea to overly limit yourself either. Combining novel datasets has been shown to incrementally increase alpha.
“If you fundamentally believe that data and having access to a lot of information about a company is better for your decision-making in terms of investing in the stock or not, then you should believe that having access to a lot of data drives the distribution of returns to the right,” says Andrej Rusakov of hedge fund Data Capital Management.
Rusakov provides an example of how layering one dataset on top of another can start to incrementally enhance alpha.
“Take any academic research on stock price movements,” continues Rusakov, “if you really do a lot of backtesting you usually end up with 50:50: as nothing really works from academia,” however, if you overlay with location data, for example, and include a strategy command to not buy when footfall is declining, it will shift the distribution to the right, “you are still not 100%..but you are maybe 55% right,” he says. Overlaying the strategy with a news sentiment filter might refine it further, says Rusakov, and “you shift the distribution even further to the right.” “Once you integrate more and more of the data sources you start to really see how the data starts to speak to you,” adds the hedge fund manager.
Sometimes it is also the case that a dataset is simply not adequate to answer the question the investor wants answered and at that point, it can sometimes be necessary to move on.
Blending the Old with the New
It is not just by layering one alternative dataset source with another that extra value can be generated - combining novel datasets with more traditional investment data can also up a strategy’s performance.
A study using RavenPack sentiment data, for example, showed how large shifts in sentiment could be used as a classifier to distinguish value stocks that were more likely to rise from a basket of hopeful turnaround candidates. The stocks were pre-selected based on more traditional factors like EPS and price-to-book.
RavenPack data has also been used as an overlay for a leveraged buyout portfolio where its sensitivity to market rumors enabled better identification of prospective buyout candidates from a portfolio of preselected stocks.
Finally, a third study by RavenPack showed how positive news sentiment and strong ESG (Environmental Social and Governance) ratings could be used as criteria for selecting portfolios of lower-risk stocks since they benefited from both the lower drawdown associated with ESG and news sentiment’s potential for alpha generation. When a further timing rule was overlaid it increased performance even more.

The conclusion seems to be that whilst it is good to become an expert in using a few quality alternative data sources, the optimum way to generate alpha is often to combine them - and traditional factors - in creative, novel ways.



