
Euclidean Technologies letter for the first quarter ended March 31, 2017.
We received many good questions about Euclidean’s last letter, where we discussed how one can use the tools of deep learning to predict companies’ future earnings. The letter referenced a paper we published recently highlighting the opportunity to systematically make earnings predictions that may improve the performance of commercially applied investment strategies that currently rely on backward-looking valuation ratios.

One interesting question we received was, “How far away are we from when machine learning can be used to deliver better earnings predictions than those made by professional Wall-Street analysts?” That is, when will the machines be performing at a level that is demonstrably as good as or even better than human?
In this letter, we talk about where we are in developing an ability to forecast earnings using machine learning. To explain our motivation for this project, we discuss our progress in the context of how Euclidean has used machine learning to explore various questions, whose answers form the foundation of our investment process.
The Original Question - What Works in Investing?
We have always been interested in whether there are timeless lessons regarding equity investing. That is, are there persistent methods for evaluating whether one company is intrinsically more valuable than another? And, does history provide a guide regarding the prices at which a company with a given set of qualities can be soundly purchased when seeking to compound wealth over long periods?
Our mental model for exploring these questions has been the analogy of how exceptional investors acquire skill through experience. By making successful and poor investments, and learning about investment history, exceptional investors can build a rich foundation of experience from which they make informed decisions about new opportunities.
Euclidean’s focus has been on using machine learning to emulate this process of building investment skill through experience. We do this by enabling our systems to examine thousands of companies and their investment outcomes across a variety of market cycles. By informing our investment process with many more distinct examples than any individual could experience in a lifetime, our goal is to find persistent patterns that lead to successful security selection. We aspire to quantify not only history’s highest-level lessons, which may be widely appreciated by other investors, but also to uncover deep and fruitful patterns that sit in the blind spots of investors’ accepted wisdom.
These goals have us navigating, what has been and remains, an incredible journey. During Euclidean’s tenure, the tools for uncovering meaningful relationships in large datasets have become increasingly sophisticated. At the same time, much more data has become available for analysis, while our experience with what it takes to successfully apply a commercial systematic strategy ever deepens. Thus, the ways Euclidean operates continue to evolve as we seek to capitalize on new insights that may improve our investment process.
How the Journey Began
In order to evaluate current investment opportunities in context of outcomes from similar situations in the past, we needed to determine what “similar” means. That is, we needed to establish ways for making comparisons between a company today and a company from years ago. The obvious challenge is that there are many different ways to determine what a comparable company is and is not. We could focus on companies’ industries, market capitalizations, revenue growth, returns on capital, earnings yields, and so on. We could make various modifications to companies’ reported financial statements to make comparisons more relevant. Moreover, even for simple concepts, such as return on capital or consistency of operations, we could consider many dozens of ways to express them and evaluate their trajectories over time.
Traditional machine learning techniques have historically required us to invest considerable thought and effort into defining this spectrum of possibilities against which similarity can be established. This step in the machine learning process is often referred to as “feature engineering.”
To understand feature engineering and its inherent limitations, you can refer to the history of automated language translation. In that domain, early versions required expert linguists to spend countless hours codifying grammatical rules and dictionary definitions, so that the machines would have a reasonable basis for learning how to translate a phrase from one language to another. These engineered machine learning approaches developed over time to become good enough that Google Translate became one of Google’s most popular services, helping more than 500 million monthly users translate over 140 billion words per day. [1]
Yet, automated language translation formed in this way remained stuck at a level of quality that was not as good as that offered by professional translators. There seemed to be just too much nuance, and too many exceptions to the rules, for the machines to deliver translations that were as good as, or better than, human experts.
Then, something happened.
The Journey Now
For much of machine learning’s history, feature engineering has been a vital part of the process. Yet, it has long been known that a form of machine learning called deep learning might alleviate the need for extensive feature engineering. You can think of deep learning as artificial neural networks, with many layers of neurons and connections that seek to directly identify complex relationships in raw data. In recent years, two impediments to realizing the promise of deep learning have been overcome:
- Deep-learning models can have orders of magnitude more parameters than existing machine learning models. This requires a level of computational power that has only recently been achieved in commodity hardware, using graphics processing units.
- Training deep neural networks (DNNs) often failed due to vanishing gradients, a challenging computation/mathematical phenomenon. To understand this challenge and the innovations that emerged to overcome it, we encourage you to read this post. [2]
With these two achievements, training deep neural networks became feasible for a wide range of problems. The opportunity emerged to spend less time on feature engineering and instead work directly with unprocessed data. With language translation, the implication was that the machines were now empowered to find the nuances and patterns in language that had previously eluded easy human codification. The result was a step-function improvement in automated language translation, as these systems began to perform at levels indistinguishable from the best professional linguists.
Here is how this relates to evaluating companies for long-term investment. The “deepness” in deep learning means we now have the opportunity for successive layers of our models to untangle important relationships from data as it is found “in the wild,” with much less pre-processing (that is, factor engineering) than has been done in the past. This introduces the possibility of finding new ways for evaluating companies, while limiting the potential for our biases to impact the learning process.
There is another important analogy between advancements in language translation and opportunities for evaluating companies. With language, words appear in sequences, and meaning can best be found by understanding the progression and context of those words. Deep learning proved to be especially successful in this domain because of the deepness of having multiple layers to a model.
“With one layer, you could only find simple patterns. With more than one, you could look for patterns of patterns.” [3]
By evaluating each word, not just on its own or as part of a phrase, but in context of the entire progression of words and sentences that surround it, deep learning can grasp the nuances and exceptions to the rules that had limited previous efforts at language translation.
Well, companies—like language—are not static. While there is information in a snapshot or trailing 12-month view into a company’s financial statements, a lot more can be understood by examining the specific path that a company’s financials have taken over time, through revenue growth, fluctuating margins, capital expenditures, debt issuance, share buybacks, and so on. Perhaps by finding patterns of patterns, which recur over time and characterize businesses that subsequently outperform or disappoint, we can further strengthen the signals we rely on when determining whether the odds will be on our side when investing in a given company.
Current Research
So, here is where we are applying these concepts. As described in our recent paper, we have introduced the way one can use deep learning to attempt to predict companies’ future earnings. Subsequently, we were asked whether these predictions might someday rival the predictive accuracy of professional Wall Street analysts.
First, we provide a quick refresher on the project, and then we explain where we are in answering that question.
Refresher on Approach
Developments in deep learning give us the opportunity to learn directly from sequences of raw financial data, thus circumventing the process of feature engineering. To the extent that feature engineering had caused us to miss important patterns in the data or caused us to introduce our own unhelpful biases, we might expect to see an improvement with these new models. Our explorations of this opportunity led us very indirectly to the idea of taking a shot at forecasting companies’ future financial results.
You see, we began with the obvious objective—we sought to build a strong investment model for forecasting returns or excess returns. We could have approached this as a regression problem (e.g., with a goal of predicting the percentile for the one-year return of a given stock) or as a classification problem (e.g., with a goal of predicting whether a stock will beat the market). In the past, Euclidean had greater success using traditional machine learning techniques when we formulated problems as classification problems. So, when we looked at deep learning, we set out to do the same thing and develop new models for predicting whether or not a stock was likely to outperform the market.
What we found was fascinating. When seeking to predict stock market outperformance, the deep-learning models would always over-fit themselves to the data. That is, the deep learning models would become too specific to the data on which they were trained, and they would show very little predictive power on new, out-of-sample data. Our interpretation of this unwelcome result is that there is so much noise in the relationship between companies’ reported results and their price changes that even if there are interesting nonlinear relationships between past financials and future prices, the deep neural networks are unable to find them.
Before we gave up on deep learning, however, we decided to try an idea related to our previous discussion on language translation, where the next word or character in a sentence is predicted from all prior words or characters. [4] That is, we decided to try using deep learning to predict future financials from past financials. It seemed likely that the relationship between historical financials and future financials should be a lot less noisy than the relationship between historical financials and future returns.
This path led to some welcome discoveries.
Results—Better Than Human?
We previously made the statement that we can use deep learning to make predictions of future earnings that meaningfully improve the simulated investment performance of certain widely researched quantitative investment strategies. Here’s specifically what that means.
We looked at earnings before interest and taxes (EBIT) divided by enterprise value (EV), which is a widely used value factor. We showed simulated results for a traditional factor model that seeks to invest in highly ranked companies as sorted by their trailing 12-month EBIT divided by current EV. Then, as a means of comparison, we showed simulated results using rankings where companies’ EV remained the same but their trailing 12-month EBITs were replaced with the model’s prediction for the companies’ EBITs one year In the future. The simulated out-of-sample results for the model using predicted EBIT showed an advantage over using trailing 12-month EBIT of approximately 2.5% a year in compounded returns. [5]
Well, while that was an encouraging observation, a number of you wondered whether those earnings predictions were better or worse than the consensus forecasts of Wall Street analysts. So, we began exploring that question.
An important caveat to these preliminary results is that—while professional analysts do make EBIT predictions—we perceive analysts really focus on and are measured on, their ability to predict earnings per share (EPS). Well, the results below reflect a comparison of the model and analyst consensus predictions of next year’s EBIT. We decided to offer these preliminary results because our work on EBIT is more advanced and because there is actually a lot of historical data on analysts’ EBIT forecasts. We are in the process of studying how the deep learning models compare to analysts in predicting EPS, as that may provide a more relevant basis for an evaluation of man vs. machine in this domain.
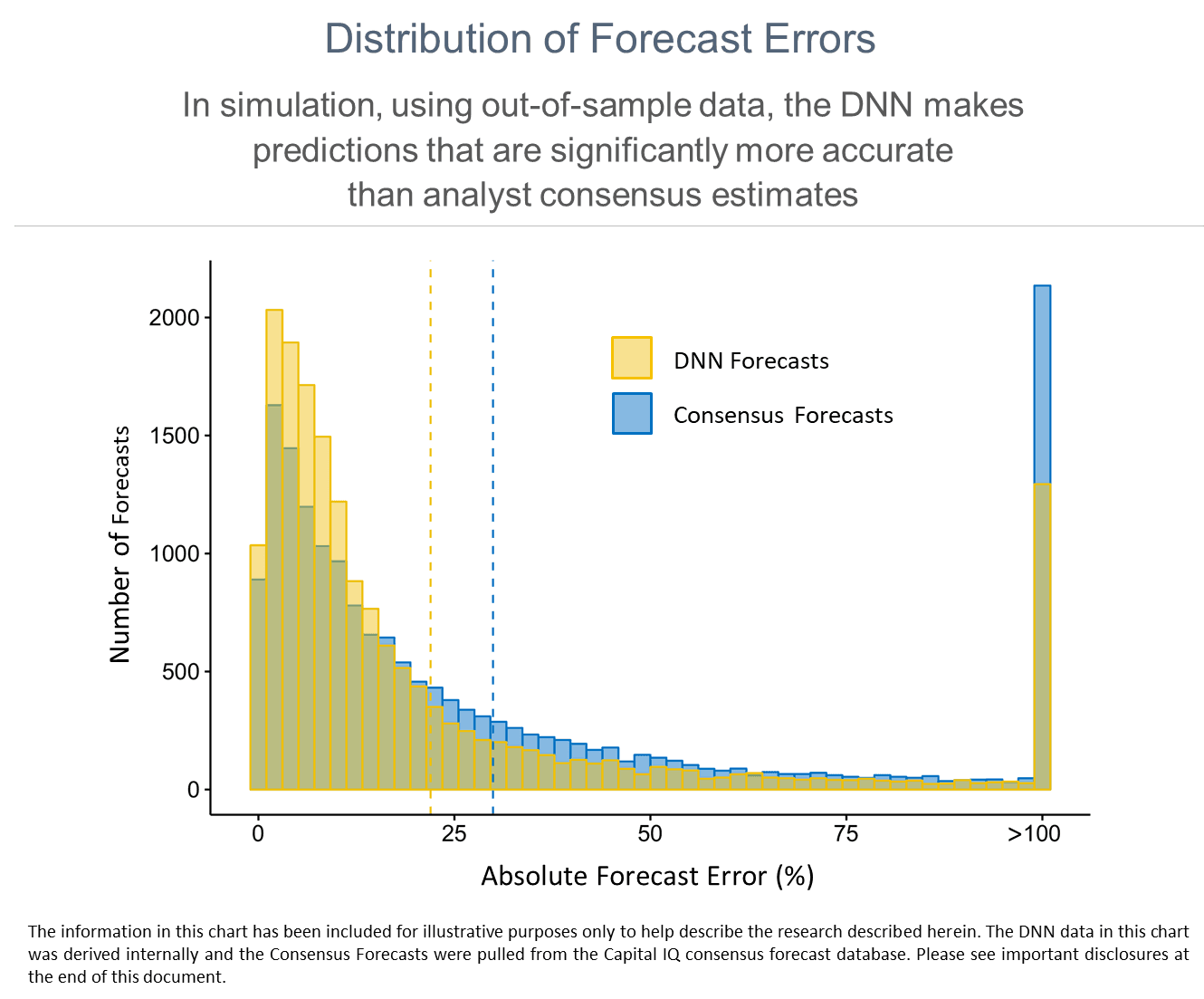
Here is the methodology: we used the Capital IQ consensus forecast database and collected all annual EBIT forecasts for companies where at least two analysts had made predictions. Then, we calculated the consensus forecast for each company using all available analyst forecasts 12 months prior to the end of fiscal years 2006–2016. For each consensus forecast, we used a DNN to make a forecast for EBIT on the same date as the analyst consensus forecast. The DNN making these predictions was trained only on data from 1970–1999 and is the same one described in the aforementioned paper, which we encourage you to review.
For each consensus and DNN forecast, we calculated the forecast error as follows:
Forecast Error = (ActualEBIT—ForecastEBIT) / |ActualEBIT|
We attempted to reduce the impact of large outliers in two ways. First, we gave |ActualEBIT| a minimum value of $100K. Second, we capped the forecast error at 100%.
Here are the results. The average DNN forecast error is 22%, which is considerably lower than the average 30% error in analyst consensus forecasts. We illustrate these results below in two ways, so that you can see the distribution of forecast errors and the consistency of these error rates across the years included in the study.

Summary
It is important to note that these predictions, which appear to be meaningfully better than analyst predictions, represent the results of a very simple recurrent neural network. There are many opportunities to improve the DNN’s predictions. Obvious ones include allowing the neural networks to access more historical financial data, companies’ earnings guidance, and unstructured data. Also, as the DNN behind these results was only trained on data through 1999, it can be improved by being iteratively trained through the present day.
We also perceive other potential intrinsic advantages for DNNs. These neural networks show no inherent optimistic or pessimistic bias, whereas professional analysts seem to have an optimistic bias and be prone to overestimating future earnings. [6] Also, neural networks can evaluate all public companies and therefore can cover the large universe of generally smaller companies that are not currently followed by Wall Street analysts.
*****
Even as we stand today, confident in our process and optimistic that the current environment will be supportive of our approach, Euclidean remains devoted to learning. We look forward to deepening our work in this area and finding promising opportunities to further enhance our investment process.
Best regards,
John & Mike
The opinions expressed herein are those of Euclidean Technologies Management, LLC (“Euclidean”) and are subject to change without notice. This material is not financial advice or an offer to purchase or sell any product. Euclidean reserves the right to modify its current investment strategies and techniques based on changing market dynamics or client needs.
Euclidean Technologies Management, LLC is an independent investment adviser registered under the Investment Advisers Act of 1940, as amended. Registration does not imply a certain level of skill or training. More information about Euclidean including our investment strategies, fees and objectives can be found in our ADV Part 2, which is available upon request.




{kind=link}